Linux基础
常用命令
常用的系统命令
1.pwd #当前位置
2.cd .. #返回上一级
3.cd + /path/ #穿越到某个路径
4.cd - #上一个路径
5.ls + /path/ #查看某文件夹下的内容
6.ls -l #当前文件夹里的文件信息(不包括子目录)
7.ls -lR #文件夹全部文件信息(包括子目录)
8.mkdir #新建文件夹
9.touch #建立文档
10.rm #删除
11.echo helloworld > new.txt #将helloworld覆盖写入文档
12.echo abc >> new.txt #将abc追加到文档末尾
13.cp /path1/2.txt /path2/3.txt #将2.txt从path1复制到path2并命名为3.txt
14.cp -r path1/file /path2 #将文件夹file从path1复制到path2不重命名
15.mv /path1/2.txt /path2/2.txt #将2.txt从path1复制到path2不重命名
16.cat #全部打印到终端
17.more #提供翻页查看
18.head -n 3 abc.txt #看abc.txt文档的前三行
19.ctrl U #清理光标前内容
20.ctrl K #清理光标后内容
21.tar cvf 2.tar 1.txt #压缩文档
22.tar xvf 2.tar #解压缩文档
23.which java #查找程序位置
VIM命令
1.Esc键 + ./hello #搜索hello字符串
2.Esc键 + :2 #跳到第二行
3.dd #删除光标所在行
4.ndd #删除光标下n行
5.yy #复制行
6.Esc键 + set nu #显示行号
7.p #粘贴
Linux用户权限划分命令
用户组:具有相同特征的用户集合,一个用户可同时在多组
1.useradd test #添加一个叫test的账户
2.usermod -g usergroup username #修改账户所属组
3.usermod -l newname username #修改账户名
4.userdel username #删除账户
5.passwd username #给某个账户重置密码
6.groups username #查看账户所属组
7.more /etc/group #查看主机账户列表
8.groupadd groupnanme #添加组
9.groupdel groupnanme #删除组
文件权限命令
用户需要一定的权限才可以操作一个程序,例如执行、打开、读取。
文件权限判断流程
- 第一次判断:判断是否为文件所有者,如果否,执行第二次判断。
- 第二次判断:判断用户是否属于有权限的组
- 如果两次全为否则当前用户则没有操作这个文件的权限。
文件权限格式
-rwxrwxrwxr 表示文件可以被读(read)
w 表示文件可以被写(write)
x 表示文件可以被执行(如果它是程序的话)
rwx也可以用数字来代替
r ————4
w ———–2
x ————1
- ————0
第1位:文件类型(d目录,-普通文件,l链接文件)
第2-4位:所属用户权限,用u(user)表示
第5-7位:所属组权限,用g(group)表示
第8-10位:其他用户权限,用o(other)表示
第2-10位:表示所有权限,用a(all)表示
符号含义
+号代表添加权限chomd +x 1.txt#给1.txt添加执行权限
-号代表剥夺权限chomd -x 1.txt#剥夺1.txt的执行权限
常见的文件权限
-rw—— (600) #只有所有者才有读和写的权限 -rw-r–r– (644) #只有所有者才有读和写的权限,组群和其他人只有读的权限 -rwx—— (700) #只有所有者才有读,写,执行的权限 -rwxr-xr-x (755) #只有所有者才有读,写,执行的权限,组只有读和执行的权限,其他人只有执行的权限 -rwx–x–x (711) #只有所有者才有读,写,执行的权限,组群和其他人只有执行的权限 -rw-rw-rw- (666) #每个人都有读写的权限 -rwxrwxrwx (777) #每个人都有读写和执行的权限 “755”构成:"0"表示没有权限、“1”表示可执行权限、“2”表示可写权限、“4”表示可读权限。“7=1+2+4,5=1+4”更改文件权限命令
1.chomd +x #添加执行权限
2.chmod -x #去除执行权限
3.chmod u(当前用户)/o(其他用户) + x #给当前/其他用户执行权限
目录权限命令
- 文件如果拥有x(执行权限)则代表可以用
cd命令进入该目录
1.chown user:usergroup 1 #修改1文件的所有者,组
2.chown -R user:usergroup filename #使用-R递归修改文件目录里面的子文件权限,只改了文件的权限,并不会修改文件里文档的权限
密码文件
/etc/passwd
- 所有用户都能查看
- 文件内容
root:x:0:0:root:/root:/bin/bash- 1、账号名称
- 2、原先用来保存密码的,现在密码都放在/etc/shadow中,所以这里显示x
- 3、UID,使用者ID。默认的系统管理员的UID为0,我们添加用户的时候最好使用1000以上的UID,1-1000范围的UID最好保留给系统用。
- 4、GID,也就是群组ID
- 5、关于账号的一些说明信息
- 6、账号的家目录,家目录就是你登陆系统后默认的那个目录
- 7、账号使用的shell
/etc/shadow
- 只有root可以查看
- 文件内容
slave1:$1$chN84aE2$tjv1V0qZm4WlO14WAAo0Z0:18782:0:99999:7:2::- 1、账户名称
- 2、加密后的密码。如果这一栏的第一个字符为!或者*的话,说明这是一个不能登录的账户。eg:
daemon:*:15259:0:99999:7:2:: - 3、最近改动密码的日期,从1970年1月1日算起,换算:
date -d "1970-01-01 18782 days" - 4、修改密码最小间隔时间。如果是 0,则密码可以随时修改;如果是 10,则代表密码修改后 10 天之内不能再次修改密码
- 5、密码需要重新变更的天数。该用户的密码会在设定天数后过期,如果为99999则没有限制
- 6、密码过期预警天数。如果在5中设置了密码需要重新变更的天数,则会在密码过期的前7天进行提醒
- 7、密码过期的宽恕时间:如果在5中设置的日期过后,用户仍然没有修改密码,则该用户还可以继续使用2天
- 8、账号失效日期,过了这个日期账号就不能用了,从1970年1月1日算起
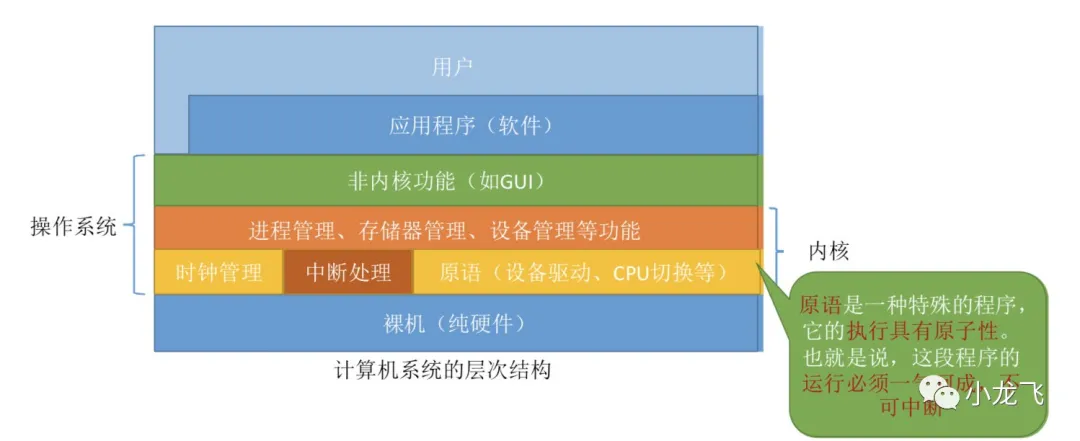
Linux 文件系统
Linux文件系统结构
Virtual File System(虚拟文件系统VFS):衔接各种各样的文件系统,VFS在用户和文件系统之间提供了一个交换层,用户和进程不需要知道文件所在的文件系统类型。隐藏了各种硬件的具体细节,把文件系统操作和不同文件系统的具体实现细节分离了开来。为所有的设备提供了统一的接口。
Buffer Cache(缓冲区缓存):将数据保留一段时间(或者随即预先读取数据以便在需要时就可用)优化了对物理设备的访问。
Device Drivers(设备驱动程序):控制操作系统和硬件设备之间的交互。
Network Interface (网络接口):提供了对各种网络标准的存取和各种网络硬件的支持。
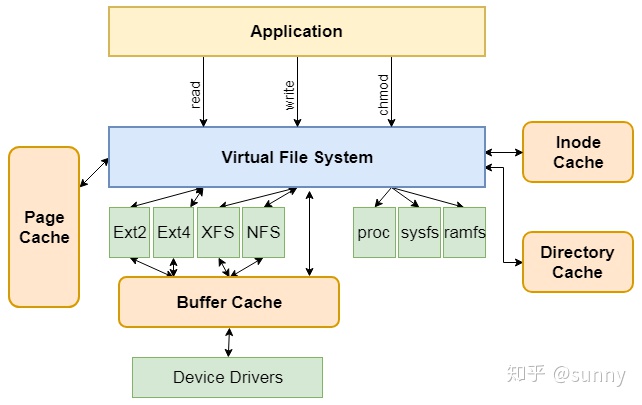
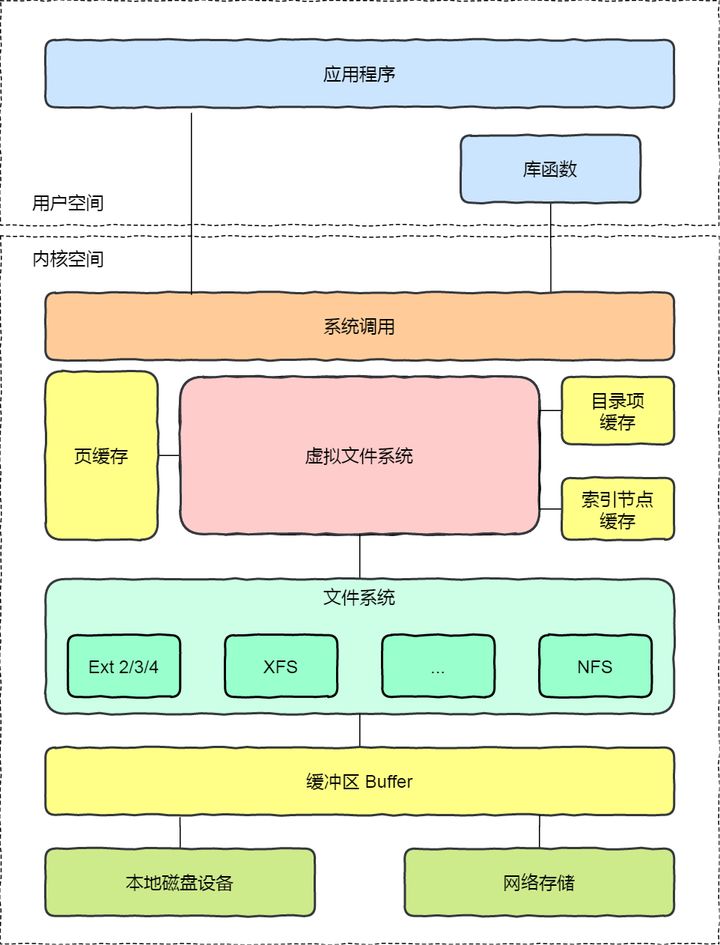
Linux文件系统
- ext:第一代的 ext 文件系统,由于它原始的时间戳(每个文件仅有一个时间戳)仅仅一年后,ext2 就替代了它。
- ext2 :早期linux中常用的文件系统,如果在将数据写入到磁盘的时候,系统发生崩溃或断电,则容易发生灾难性的数据损坏.
- ext3 :ext2的升级版,带日志功能。日志是磁盘上的一种特殊的分配区域,其写入被存储在事务中。
- 日志的应用
- 如果该事务完成磁盘写入,则日志中的数据将提交给文件系统自身。
- 如果系统在该操作提交前崩溃,则重新启动的系统识别其为未完成的事务而将其进行回滚,就像从未发生过一样。正在处理的文件可能依然会丢失,但文件系统本身保持一致,且其它所有数据都是安全的。
- ext3 文件系统的 Linux 内核中实现了三个级别的日志记录方式: 日记(journal)、 顺序(ordered)和 回写(writeback)
- 日记(journal):最低风险模式,在将数据和元数据提交给文件系统之前将其写入日志。这可以保证正在写入的文件与整个文件系统的一致性,但其显著降低了性能。
- 顺序(ordered):顺序模式将元数据写入日志而直接将数据提交到文件系统。这里的操作顺序是固定的,这么做可以减少数据回滚量。
- 元数据提交到日志;
- 数据写入文件系统;
- 将日志中关联的元数据更新到文件系统
- 回写(writeback):最不安全的日志模式。元数据会被记录到日志,但数据不会。元数据和数据都可以以任何有利于获得最佳性能的顺序写入。虽然显著提高性能,但安全性低很多。在崩溃或崩溃之前写入的文件很容易丢失或损坏。
- 日志的应用
- ext4 :linux常用文件系统格式,支持大文件系统,提高了对碎片的抵抗力,有更高的性能以及更好的时间戳。
- ext3 和 ext4的差别:
- 兼容性。允许 ext3 文件系统原地升级到 ext4;允许ext4 驱动程序以ext3 模式自动挂载ext3 文件系统
- 寻址地址。ext3 文件系统使用 32 位寻址,ext4 使用 48 位的内部寻址
- 性能更好。
- ext3 和 ext4的差别:
Linux文件类型
- 普通文件(-)
- 从Linux的角度来说,类似mp4、pdf、html这样应用层面上的文件类型都属于普通文件
- 目录文件(d,directory file)
- 符号链接(l,symbolic link)
- 这种类型的文件类似Windows中的快捷方式,是指向另一个文件的间接指针,也就是常说的软链接
- 块设备文件(b,block)和字符设备文件(c,char)
- 这些文件一般隐藏在/dev目录下,在进行设备读取和外设交互时会被使用到
- 比如磁盘光驱就是块设备文件,串口设备则属于字符设备文件
- 系统中的所有设备要么是块设备文件,要么是字符设备文件
- 管道(FIFO)文件(p,pipe)
- 管道文件主要用于进程间通讯。比如使用
mkfifo命令可以创建一个FIFO文件,启用一个进程A从FIFO文件里读数据,启动进程B往FIFO里写数据
- 管道文件主要用于进程间通讯。比如使用
- 套接字(s,socket)
- 用于进程间的网络通信,也可以用于本机之间的非网络通信
Linux文件目录
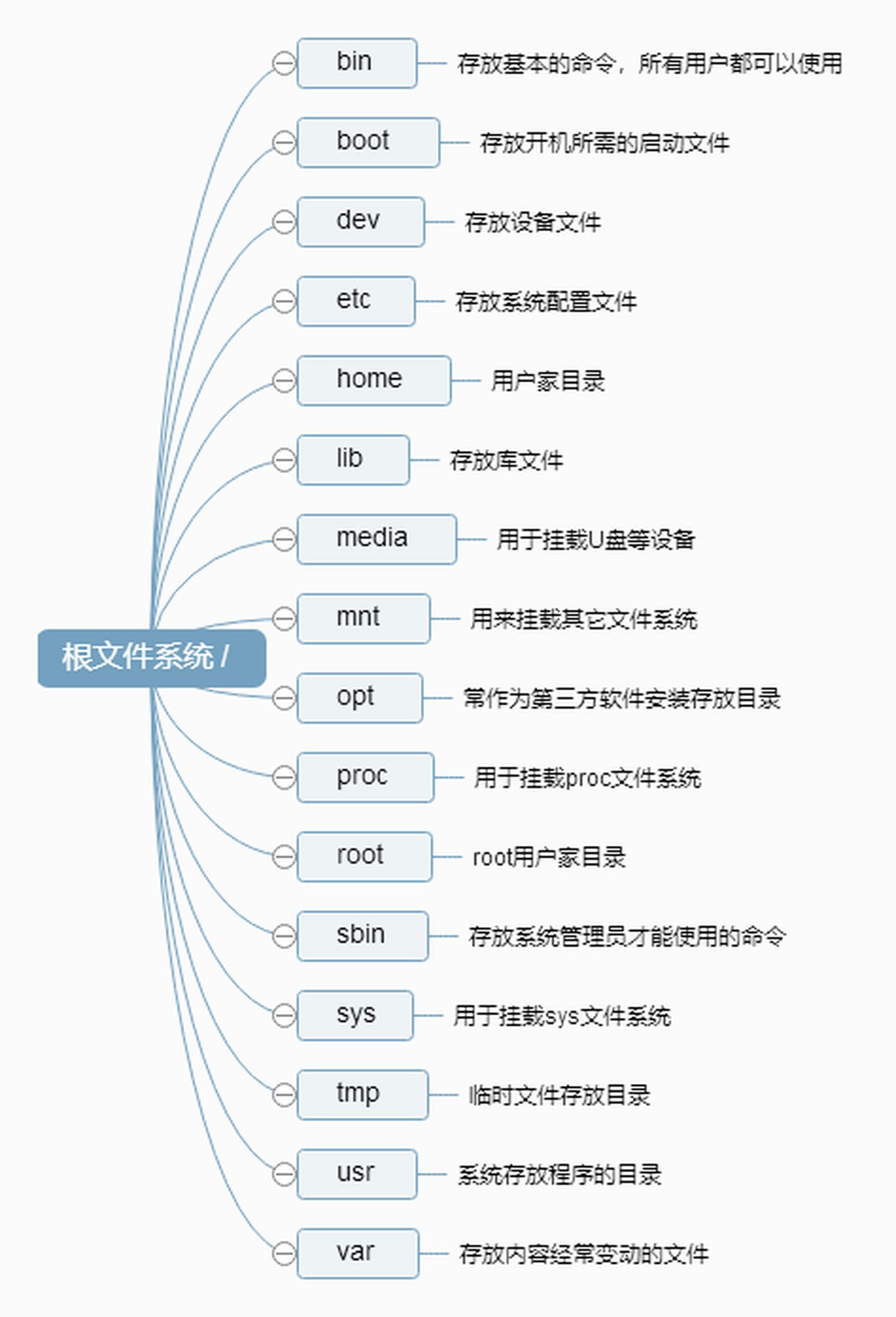
Linux文件系统特性
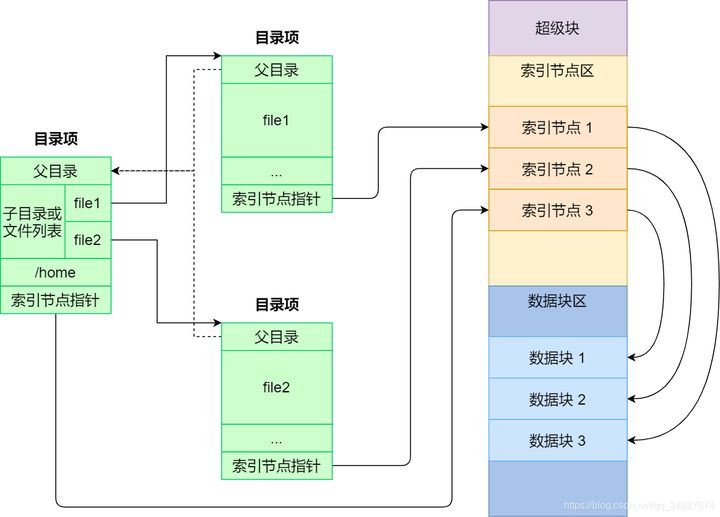
Linux读取一个文件的流程:
1.先读取这个文件inode块里面存放的所有索引号码。
2.按照号码去寻找对应的block块。
3.最后读取block块里面的内容。
就像一本书有封面、目录和正文一样。在文件系统中,超级块就相当于封面,从封面可以得知这本书的基本信息;inode 块相当于目录,从目录可以得知各章节内容的位置;而数据块则相当于书的正文,记录着具体内容。
前置知识
- 在Linux中,一个文件分为两个部分。一个是文件的权限和属性,另外一个是文件的具体内容。这两者分别存放在inode块和block块中。
- 每个block块都有一个索引号码,这个索引号码会被记录在inode里面
- 索引节点( inode)它是文件系统的最基本单元,是文件系统连接任何子目录、任何文件的桥梁。用来记录文件的元信息,比如 inode 编号、文件大小、访问权限、创建时间、修改时间、数据在磁盘的位置等等。索引节点是文件的唯一标识,它们之间一一对应,会被存储在硬盘中,所以索引节点同样占用磁盘空间。
- 为了减少读盘次数,内核缓存了目录的树状结构,称为dentry cache。dentry cache只保存最近访问过的目录项,如果要找的目录项在cache中没有,就要从磁盘读到内存中。
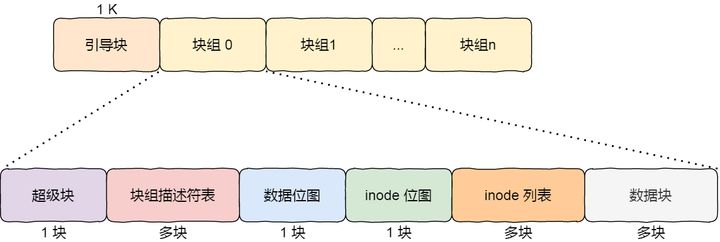
引导块:在系统启动时用于启用引导
超级块:包含整个文件系统的基本信息。如块大小,inode/block的总量、使用量、剩余量,指向空间 inode 和数据块的指针等相关信息
块组描述符:包含文件系统中各个块组的状态。比如块组中空闲块和 inode 的数目等
数据位图和 inode 位图:用于表示对应的数据块或 inode 状态
inode table:包含了所有的 inode
数据块:实际记录文件的内容。若文件太大时,会占用多个block
例子:读取2.txt这个文本文件,它的路径是/root/1/2.txt
1.根据inode查找文件:
查找根目录“/”
查找/root/文件夹
查找/root/1/文件夹
查找/root/1/2.txt文本文件
[root@slave1 1]# ls -dil / /root/ /root/1/ /root/1/2 64 dr-xr-xr-x. 17 root root 224 6月 4 01:24 / #先读取根目录“/”,根目录即挂载点的inode号码是64 8409153 dr-xr-x---. 7 root root 277 8月 17 23:18 /root/ #通过编号为64的inode块找到/root/对应的block块,返回/root/对应的inode号码是8409153。 7073042 drwxr-xr-x. 2 root root 15 8月 17 20:57 /root/1/ #通过编号为8409153的inode块来找到/root/1/对应block块,返回/root/1/对应的inode号码是7073042。 7073049 -rw-r--r--. 1 root root 11 8月 17 20:55 /root/1/2 #通过编号为7073042的inode块来找到/root/1/2.txt对应block块,返回/root/1/2.txt对应的inode号码是7073049。最后在7073049这个inode中找到2.txt
2.读取文件
- 从inode找到所有block块的索引号
- 根据索引号找到block块
- 读取具体内容
硬链接:一般情况下,文件名和inode号码是”一一对应”关系,每个inode号码对应一个文件名。但是,Linux系统允许,多个文件名指向同一个inode号码。A,B互不干涉
ln <源文件B><新文件A>
软链接(符号连接):文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。如果删除了B,A失效。
ln -s <源文件B><新文件A>
硬链接和软链接的区别:
- 硬链接原文件和新文件的inode编号一致。而软链接不一样。
- 对原文件删除,会导致软链接不可用,而硬链接不受影响。
- 对原文件的修改,软、硬链接文件内容也一样的修改。
Linux的引导和启动
操作系统的启动分为两个阶段:引导和启动。
引导阶段:开始于打开电源或者重启,结束于内核初始化完成和 systemd 进程成功运行。
启动阶段:开始于引导阶段结束,结束于操作系统进入可操作状态。
引导过程
- BIOS 上电自检(POST)
- 引导装载程序 (GRUB2)
- 内核初始化
- 启动 systemd,其是所有进程之父
BIOS 上电自检(POST)
- 上电自检主要由硬件部分来完成。
- BIOS 上电自检
- 确认硬件的功能正常
- 查找引导扇区
- 有效引导记录的第一个引导扇区被装载到内存中,并且控制权也转移到此段代码。
引导装载程序 (GRUB2)
GRUB2 是一个用于计算机寻找内核并加载其到内存的程序。
1.BIOS 查找MBR(主引导记录)
2.加载 Linux 内核到内存,转移控制权到内核
3.内核(压缩格式)自解压完成,则加载 systemd进程并转移控制权到 systemd
4.systemd启动,引导过程的结束。此刻,Linux 内核和 systemd 处于运行状态
启动过程
启动过程使 Linux 系统进入可操作状态,并能够执行用户功能性任务。
启动systemd
systemd 是所有进程的父进程,它负责将 Linux 主机带到一个用户可操作状态(可以执行功能任务)。
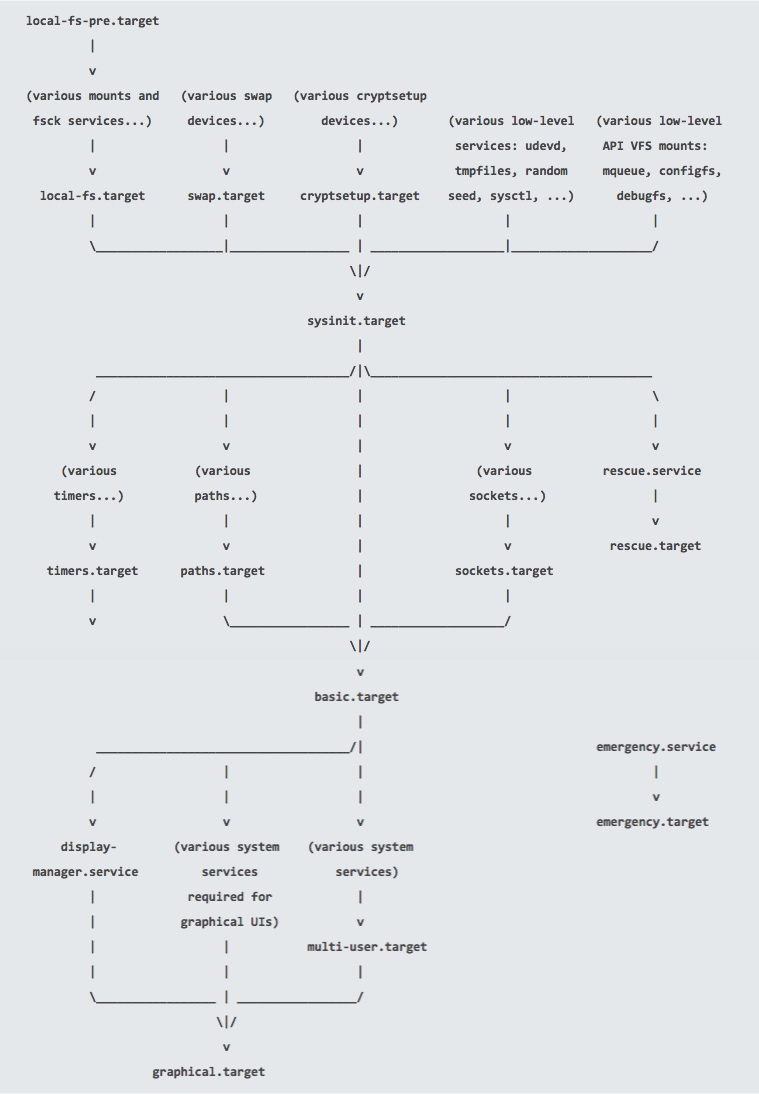
- 在
sysinit.target的条件满足以后,systemd 接下来启动basic.target,启动其所要求的所有单元。 - 用户级目标态(
multi-user.target或graphical.target) 初始化。multi-user.target必须在图形化目标态graphical.target之前先达成。
启动完成标志
以 * 开头的目标态是通用的启动状态,说明系统已经启动完成。eg: *graphical.target or *multi-user.target
- 如果
multi-user.target是默认的目标态,则系统以命令行登录界面呈现于用户。 - 如果
graphical.target是默认的目标态,则系统以图形登录界面呈现于用户。
Windows基础
Windows引导和启动
目前主要的系统引导方式有两种:
1.传统BIOS + MBR
2.新型UEFI + GPT
UEFI BIOS可同时识别MBR分区和GPT分区,所以MBR和GPT磁盘都可用于启动操作系统。但是UEFI只能将系统安装在GPT磁盘中。
UEFI:微型操作系统,能够识别FAT文件系统,运行efi程序。
传统BIOS + MBR
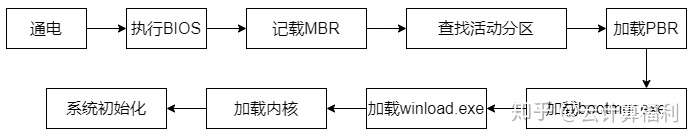
1.上电,执行Legacy BIOS.
2.进行POST自检,完成硬件初始化。
3.查找MBR中的IPL(用于确定活动主分区),找到IPL的引导扇区(位于第一个扇区)中的引导记录(PBR),载入PBR中的启动管理器(bootmgr.exe或NTLDR)。
4.bootmgr.exe读取IPL根目录下boot文件夹里的启动设置文件(BCD或boot.ini),然后载入程序winload.exe(位置:C:\Windows\system32\winload.exe)来加载OS内核。
5.内核程序执行系统初始化。
新型UEFI + GPT

1.开机,执行UEFI BIOS。
2.UEFI BIOS先直接初始化CPU和内存,CPU和内存若有问题则直接黑屏,其后启动PXE采用枚举方式搜索各种硬件并加载驱动,完成硬件初始化。
3.从EFI分区(不一定第一个扇区)找到、读入、执行启动管理器(\efi\Microsoft\boot\bootmgfw.efi)。
4.bootmgfw.efi导入EFI分区BCD文件(efi\Microsoft\BCD),然后载入程序winload.efi(位置:C:\Windows\system32\winload.efi)来加载OS内核。
Tips:BCD是一个数据库文件,如果包含多个系统,信息会包含在BCD中,通过显示一个系统列表供用户选择。
Windows用户管理
每个账户有自己唯一的SID(安全标识符)
账户组作用:简化权限赋予
本地账户与域账户
Windows账户分为本地用户账户和域账户两种。
- 本地帐户是本机建立的用户帐户
- 域账户是域服务器上由管理员分配给你的帐户。
本地用户账户和域账户的区别:
1.本地用户账户存储在本地的sam数据库中,而域账户存储在AD(active directory)中。
2.使用本地用户账户的时候,用户只能使用该账户登录到本地计算机上,而使用域账户用户可以在整个域环境中所有的计算机上进行登录。
3.本地账户只能在账户所属的计算机上进行管理,每个计算机上的管理员单独管理自己机器上的本地账户。而域账户通过AD用户和计算机管理工具进行统一的管理。
常见内置组
1)Administrators:管理员组
2)Backup Operators:具有备份还原权限的组
3)Guests:来宾组
4)Network :网络配置组
5)Remote:远程桌面组
6)Users:新用户默认组
7)Print :打印机组
特殊本地内置组
9)Everyone:任何一个用户都属于这个组
10)Authenticated Users:任何使用有效用户来登录此计算机的用户,都属于此组
11)Interactive:任何在本地登录(按ctrl+alt+del键登录)的用户,都属于此组
12)Network:通过网络登录此计算机的用户,都属于此组
组管理命令
1.net localgroup #输出所有组
2.net localgroup groupname #输出指定组的成员
3.net localgroup groupname /add #添加组
4.net localgroup groupname /del #删除组
5.net localgroup groupname username /del # 从组中踢出用户
6.net localgroup groupname username /add # 添加用户到组
内置账户
内置账号无法删除
1.administrator #管理员
2.system #系统账户,最高权限
3.local services #本地服务账户,user的权限
4.network services #网络服务账户,user权限
用户管理命令
1.net user #输出所有用户
2.net user kk password #修改用户kk的密码
3.net user ko password /add #添加新用户ko
4.net user ko /del #删除ko用户
Windows文件系统
文件系统,就是文件的储存方式。
每个驱动器都有自己的根目录结构,这样形成了多个树并列的情形,如图所示:
常见的文件系统
NTFS(最常用)
FAT32
FAT(FAT16)
ExFAT
FAT:在软盘、闪存(U盘),以及很多嵌入式设备上常见,16位,支持的分区最大为2GB。
FAT32: 兼容性好,是为32位计算机设计的,每个簇容量都固定为4KB(32位),文件不能超过 2^32 - 1 个字节( 4GB)。分区容量下限是512MB,不同操作系统的上限不同,最大不超过2TB ,一般系统32GB 。例如Win2000最大支持32GB FAT32分区,而WinXP最大可达2TB FAT32分区。
ExFAT(FAT64):ExFAT是专门为闪存设计的文件系统,单个文件的存放和传输突破了4GB的限制。兼容性好,在windows、Linux、Mac系统上都是可以读写。
NTFS:采用“日志式”的文件系统,记录磁盘的详细读写操作,最大支持的独立分区是2TB。
在稳定性和安全性方面,NTFS要优于FAT32,但是FAT32兼容较旧的存储设备及系统,如DOS系统等。两者的主要区别体现在:
1.FAT32不支持存放和传输超过4G的单个文件
2.NTFS无法运行在DOS系统下,FAT32则可以兼容DOS系统
FAT32与exFAT的区别:
大多数U盘在格式化时选用FAT32为默认文件系统。它最大优点就是在一个不超过8GB的分区中,FAT32分区格式的每个簇容量都固定为4KB,可以大大地减少磁盘的浪费,提高磁盘利用率。
- 比如传输12k的文件。FAT32每个簇4K,占三个簇,浪费0K。exFAT每个簇256K,占一个簇,浪费244K。
NTFS相比FAT会让闪存性能降低
- NTFS因为要记录磁盘的详细操作,对U盘这种快闪存储介质会造成较大的负担。
- 比如同样存取一个文件,在 NTFS系统上的读写次数就会比FAT32多,理论上NTFS格式的U盘比较容易损坏。
- U盘带宽有限,NTFS文件系统频繁读写占据通道会让磁盘性能降低。
Windows服务
Microsoft Windows 服务可以在 Windows 中长时间运行应用程序,非常适合需要长时间运行功能时使用。
Windows注册表
概述
注册表是Microsoft Windows中的一个重要的数据库,用于存储系统和应用程序的设置信息,在运行中输入regedit即可进入。
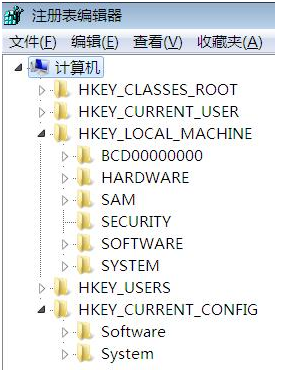
注册表的组成结构
注册表由键(
key,或称“项”)、子键(subkey,子项)和值项(value)构成的hive文件。注册表的结构是一个树状结构。一个键(
key,或称“项”)就是一个节点,子键(subkey)就是这个节点的子节点,子健也是键。键的一条属性被称为一个value(值项),value由名称、类型、数据类型和数据组成。一个键可以有多个值,每个值的名称不同,如果值名称是空,则该值为该键的默认值。5个根键: 1.HKEY_CLASSES_ROOT 说明:启动应用程序所需的全部信息。 2.HKEY_CURRENT_USER 说明:当前登录用户的配置信息。 3.HKEY_LOCAL_MACHINE 说明:本地计算机的系统信息,包括硬件和操作系统信息,安全数据和各类软件设置信息。 4.HKEY_USERS 说明:所有用户的配置数据,这些数据只有在用户登录系统时才能访问。 5.HKEY_CURRENT_CONFIG 说明:硬件的配置信息,从HKEY_LOCAL_MACHINE中映射出来。
注册表基本数据类型
二进制值(reg_binary):多数硬件信息以二进制数据存储,以十六进制格式显示在注册表编辑器中
字符串值(reg_sz):包括字符串的注册表键,使用字符串数据类型
双字节值(reg_dword):4个字节的32位信息。它在出错控制功能上用处极大,其数据一般以十六进制格式显示在注册表编辑器中
多字符串值(reg_multi_sz):将一系列项目作为单独的一个值。对于多种网络协议、多个项目、设备列表以及其他类似的列表项目来说,可以使用多字符串值
可扩充字符串值(reg_expand_sz):代表一个可扩展的字符串
Windows进程
概念
- 进程是程序在处理器上的的一次动态执行过程,是程序执行的一个实例。
进程的组成
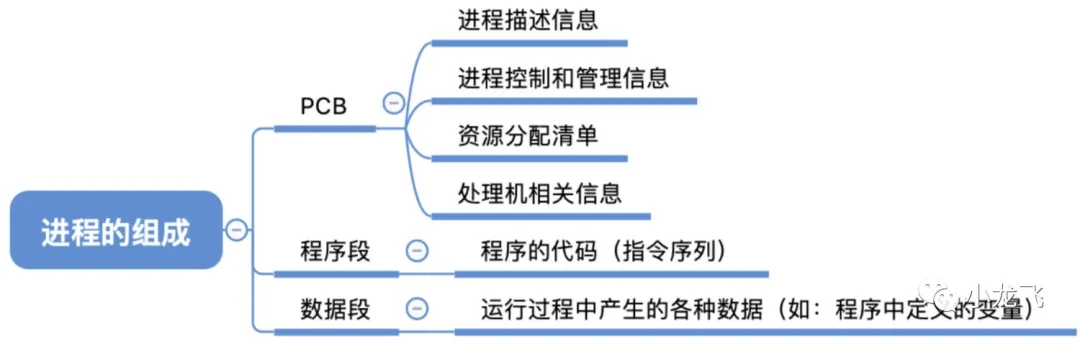
进程控制块(PCB):用来描述进程的数据结构。每个进程都维护了一个PCB,用来保存与该进程有关的各种状态信息,主要包括以下信息
- 进程描述信息
- 进程标识符,每个进程都有一个唯一的标识号。
- 用户标识符进程归属的用户,用户标识符主要为共享和保护服务。
- 进程控制和管理信息
- 描述进程当前的状态信息(就绪、运行)。
- 进程优先级,描述进程抢占处理机的优先级。
- 进程间通信信息。
- 使用的资源关联信息。
- 资源分配清单
- 用于说明内存地址空间或虚拟地址空间的状况。
- 所打开文件的列表和所使用的输入/输出设备信息。
- 处理机相关信息
- 用户可见寄存器,控制和状态寄存器如程序计数器,程序状态字;
- 栈指针,系统带调用/中断处理和返回时需要用到它。
- 进程描述信息
程序段:被进程调度程序调度到CPU执行的程序代码段。程序可被多个进程共享,即多个进程可以运行同一个程序。
数据段:可以是程序加工处理的原始数据,也可以是程序执行时产生的中间或最终结果。
共享区域:多个进程共享操作系统代码、内存、数据。
系统栈:用于返回。保存调用参数,返回值和返回地址。
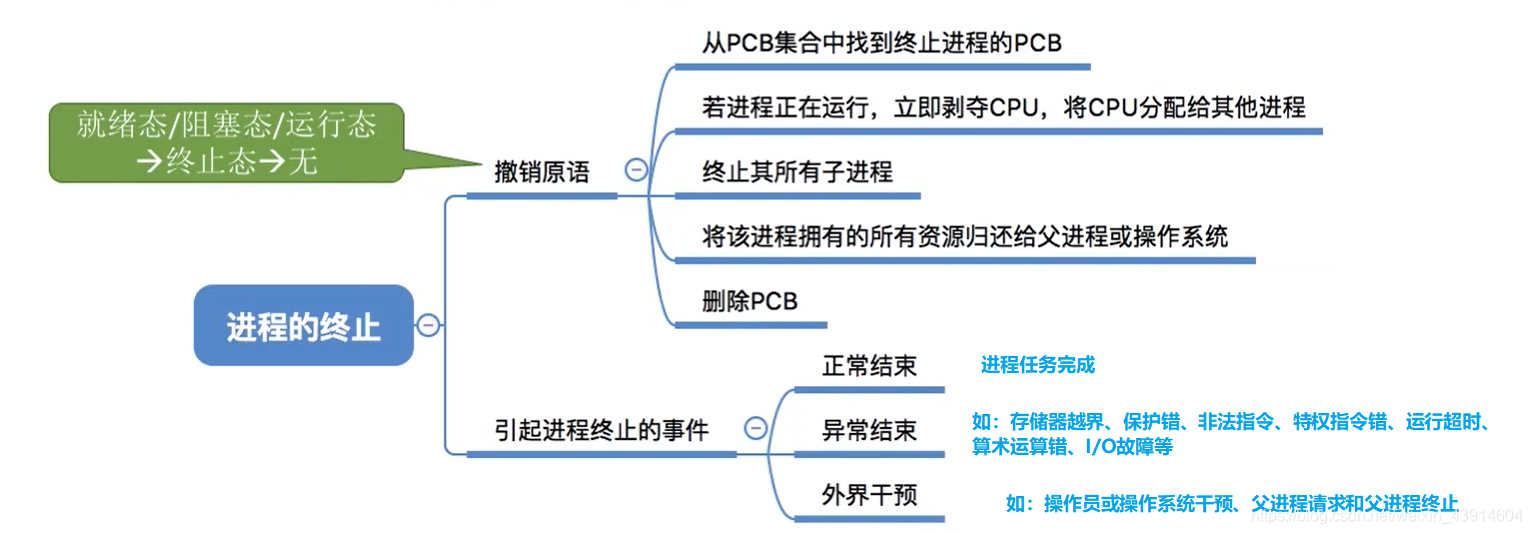
进程的五状态模型
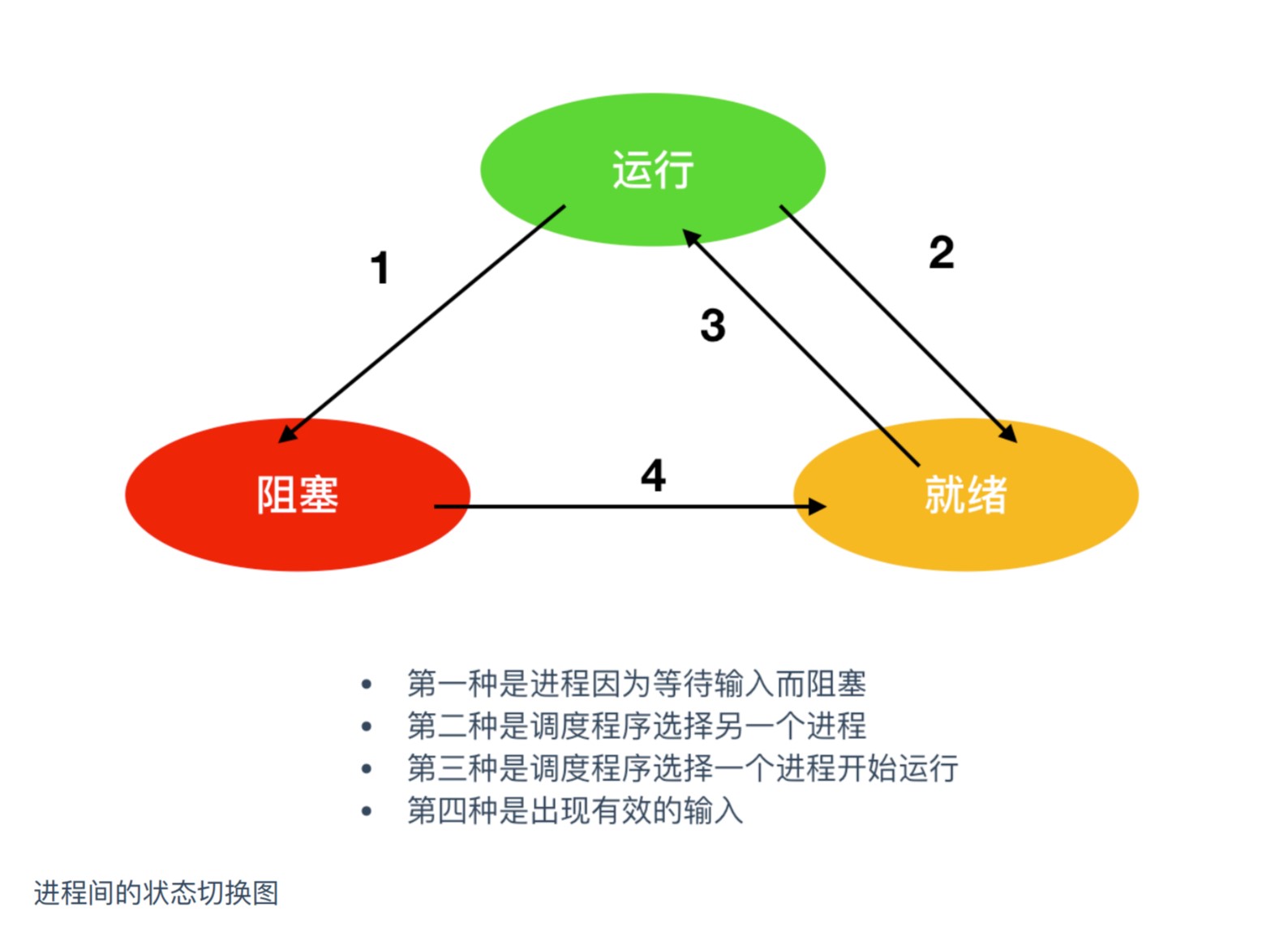
- 创建态:进程正在被创建时,操作系统会为进程分配资源、初始化PCB;
- 就绪态:当进程创建完成后,便进入“就绪态”, 处于就绪态的进程已经具备运行条件, 但由于没有空闲CPU,就暂时不能运行;
- 运行态:进程此时在CPU上运行,那么这个进程 处于“运行态”。CPU会执行该进程对应的程序(执行指令序列);
- 阻塞态:进程运行的过程中,可能会等待某个事件的发生(如等待某种系统资源的分配,或者等待其他进程的响应)。在这个事件发生之前,进程无法继续往下执行,此时操作系统会 让这个进程下CPU,并让它进入“阻塞态”。当CPU空闲时,又会选择另一个“就绪态”进程上CPU运行;
- 终止态:进程执行 exit 系统调用,请求操作系统终止该进程。此时该进程会进入“终止态”,操作系统会让该进程下CPU, 并回收内存空间等资源,最后还要回收该进程的PCB。当终止进程的工作完成之后,这个进程就彻底消失了。
进程的七状态模型
七状态模型是在五状态模型上新增了阻塞挂起和就绪挂起状态
背景:在五状态模型中,一个进程被允许进入,就会被完全载入内存。但是I/O活动的速度比处理器慢得多,因此所有进程都处于阻塞(等待某事件)状态比较常见,所以会占用大量内存,使得新进程的进入请求无法满足。
解决:把处于阻塞态的进程从内存换到磁盘中去,加入到“挂起队列”。
阻塞挂起态:进程在外存中并等待一个事件。
- 阻塞态→阻塞挂起态:1.没有就绪进程,将其换出。2.即使有就绪进程,为满足系统基本性能需求也会换出。
- 阻塞挂起态→阻塞态:阻塞挂起态进程优先级高于所有就绪态进程且阻塞进程的事件很快就会发生。
就绪挂起态:进程在外存中,但只要被载入内存就可以被调度执行。
- 就绪挂起态→就绪态:内存中没有就绪态进程,就会将其调入就绪态。
- 就绪态→就绪挂起态:1.得到足够空间的唯一方法是挂起一个就绪态进程时。2.高优先级阻塞态进程很快就绪。
进程控制
用“原语实现”进程的控制
为什么要使用原语对进程控制呢?
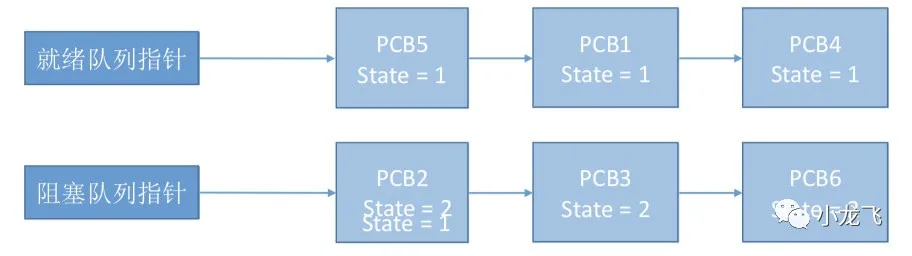
在上图中,假设PCB中的变量 state 表示进程当前所处状态,1表示就绪态,2表示阻塞态,假设此时进程2等待的事件发生了,则操作系统中,负责进程控制的内核程序至少需要做这样两件事:
- 1.将PCB 2的 state 设为 1;
- 2.将PCB 2从阻塞队列放到就绪队列;
完成了第一步后收到中断信号,那么PCB 2 的 state=1,但是它却被放在阻塞队列里,主要原因就是第一,第二步操作不是一个原子操作。
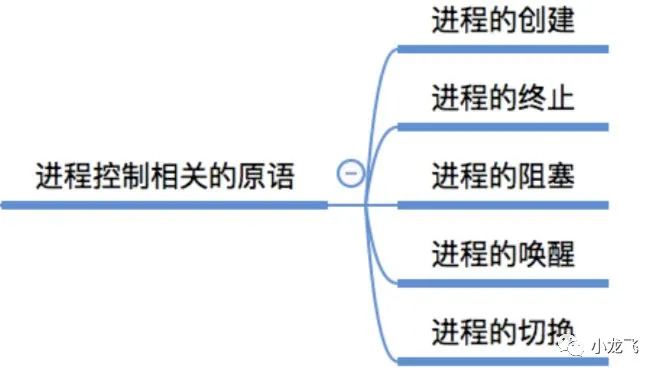
用原语实现进程控制。原语特点是执行期间不允许中断,即:原子操作。
- 原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序不可以被打乱,也不可以被切割而只执行其中的一部分。
- 也就是说,利用这一性质,中断机制将处于关闭状态,直到运行完两步才会接受中断,如此就不会出现上述的矛盾情况。
进程控制五大原语
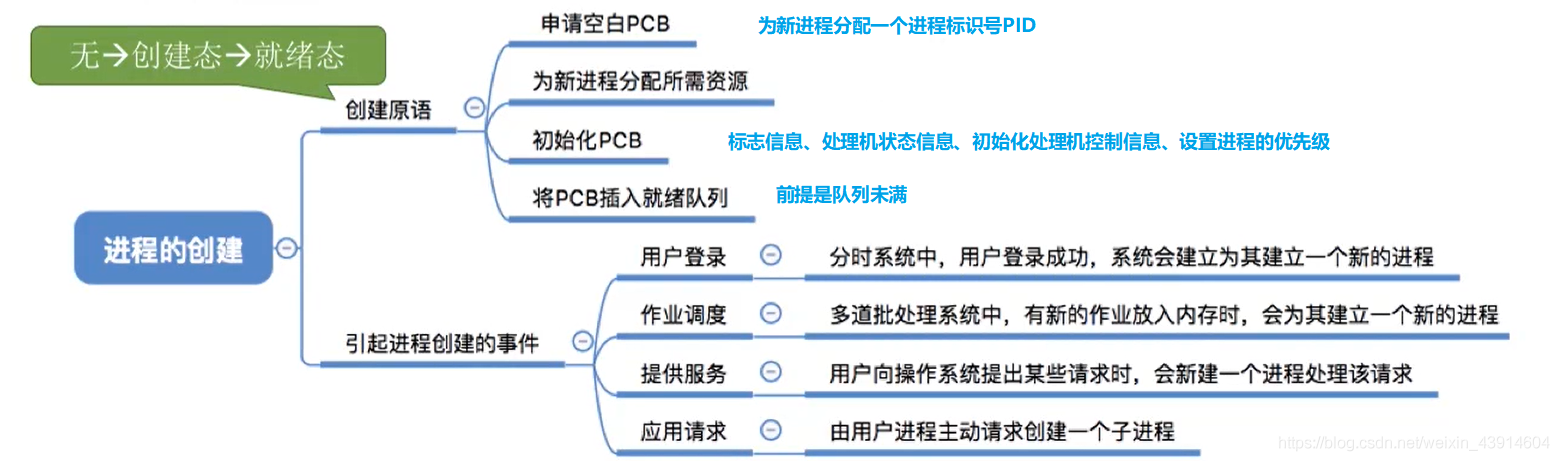
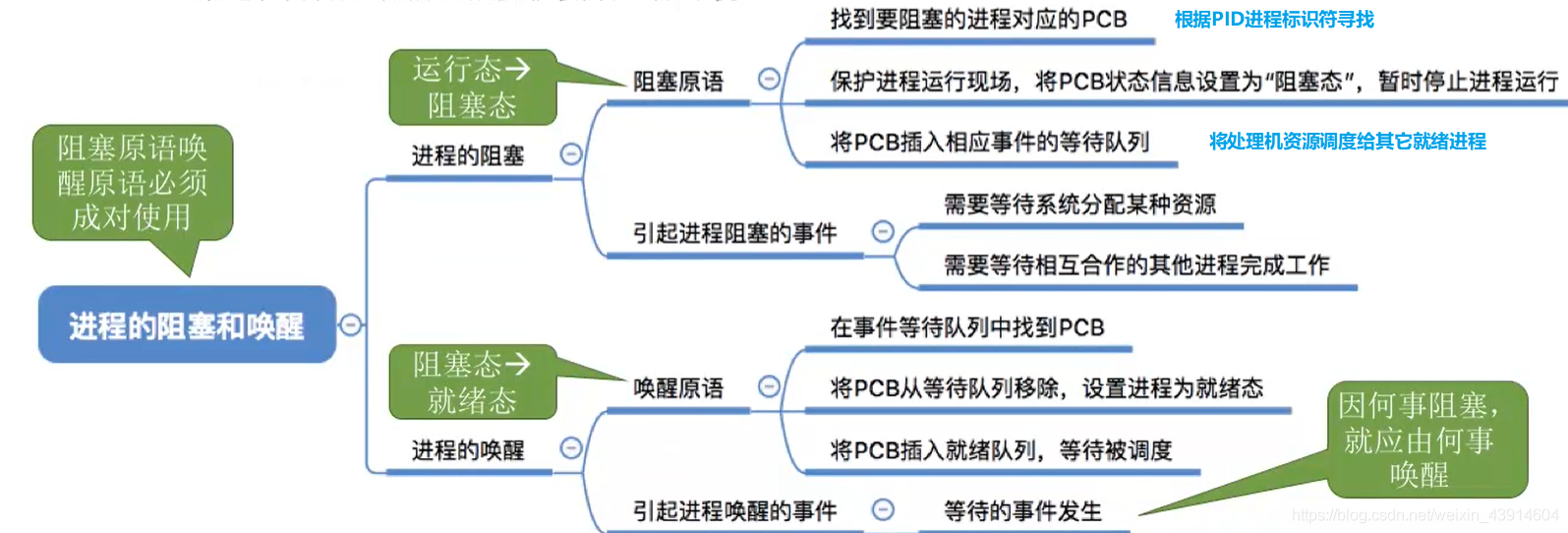
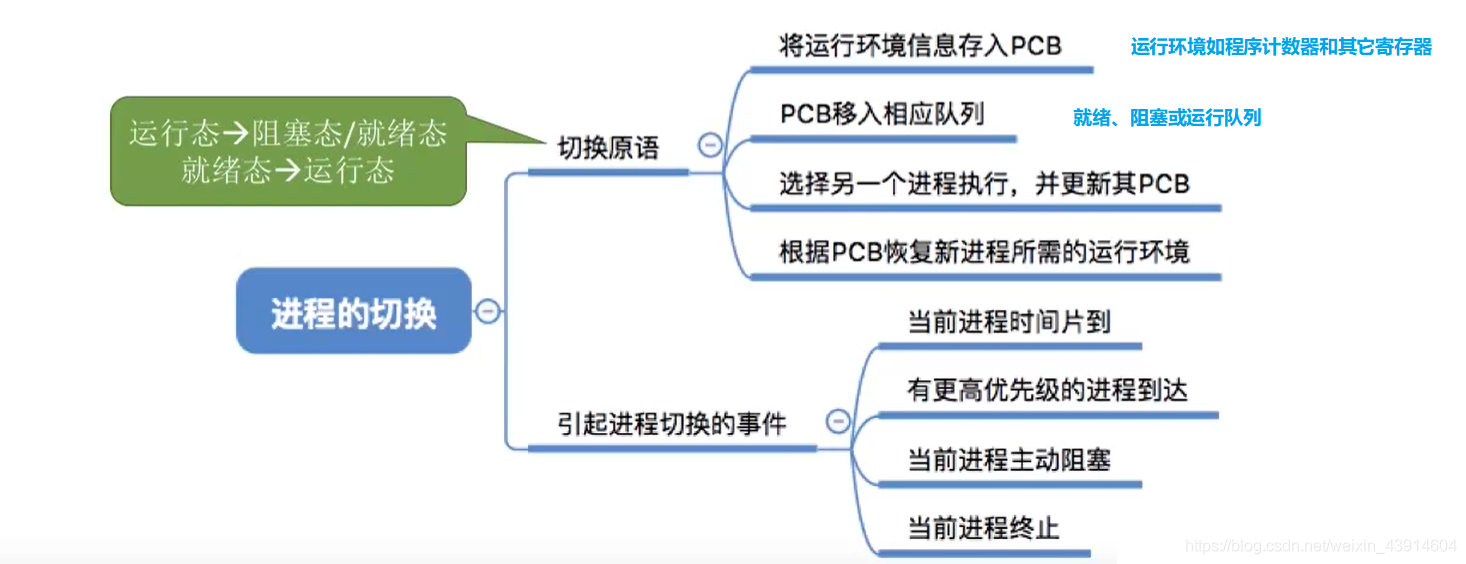
进程控制原语都在做三件事:
- 更新PCB信息
- 所有的进程控制原语一定都会修改进程状态标志;
- 剥夺当前运行进程的CPU使用权必然需要保存其运行环境;
- 某进程开始运行前必然要恢复其运行环境;
- 将PCB插入合适的队列
- 分配/回收资源
进程通信
进程通信就是指进程之间的信息交换
进程通信分为共享存储,消息传递,管道通信
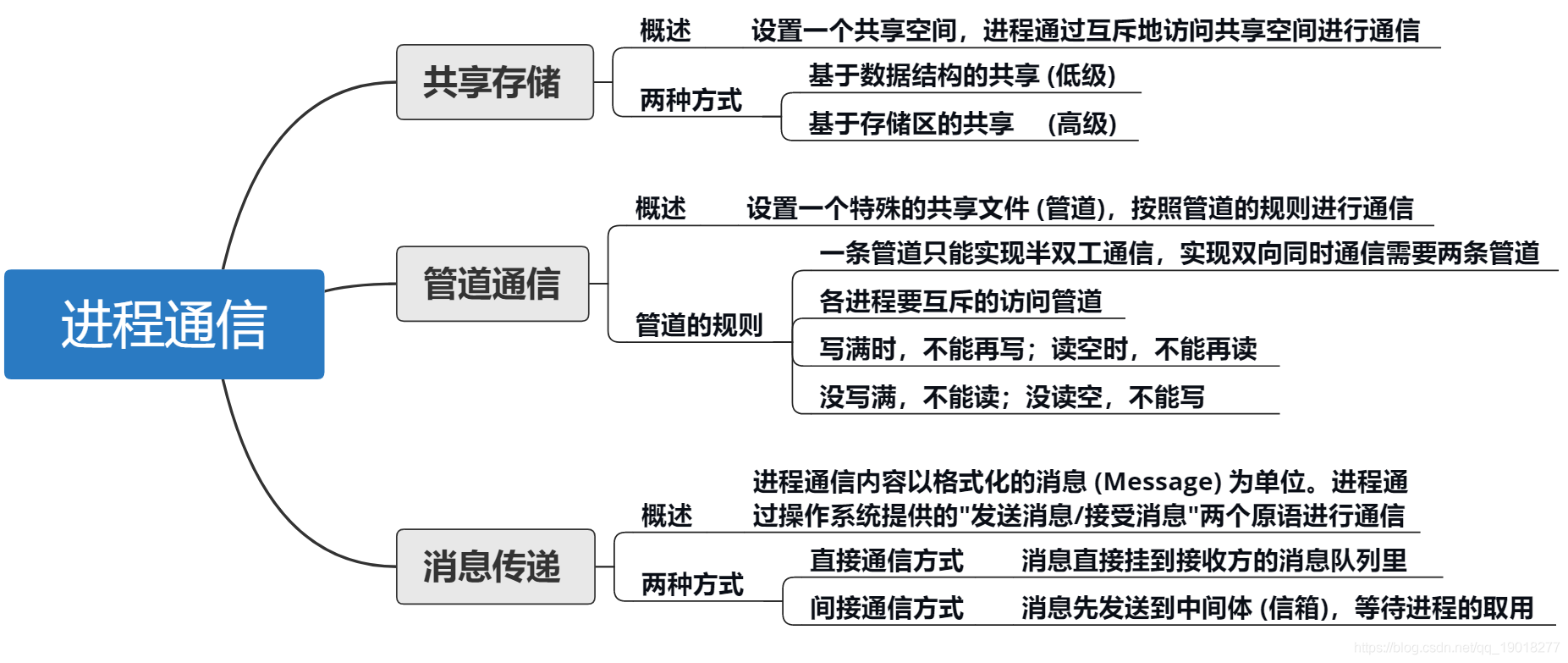
共享存储
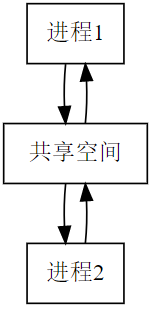
- 进程是分配系统资源的单位(包括内存地址空间),因此各进程拥有的内存地址空间相互独立,如1001这个地址空间不能够同时给两个进程。为了保证安全,一个进程不能直接访问另一个进程的地址空间。
- 共享存储分为两种
- 1.基于数据结构的共享:比如共享空间里只能放一个长度为10的数组(由用户负责控制设置数据结构)。这种共享方式速度慢、传输数据少、限制多,属于低级通信方式;
- 2.基于存储区的共享:在内存中画出一块共享存储区,通过对该共享区的读/写交换信息实现通信,数据的形式、存放位置都由进程控制,而不是操作系统。相比之下,这种共享方式速度更快、传输数据量更大,是一种高级通信方式。
管道通信
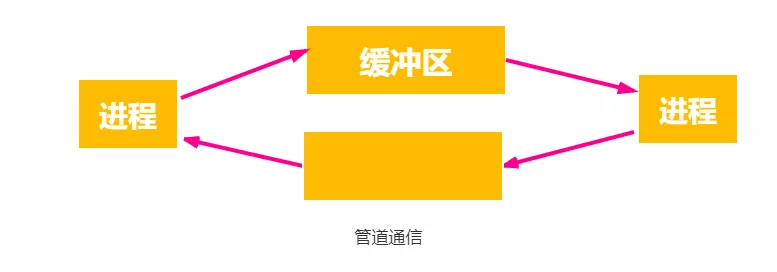
“管道”是指用于连接读和写进程的一个共享文件,又名pipe 文件。其实就是在内存中开辟 一个大小固定的缓冲区。
- 管道只能采用半双工通信,某一时间段内只能实现单向的传输。如果要实现双向同时通信,则需要设置两个管道;
- 各进程要互斥地访问管道,即一个进程正在访问临界资源,另一个要访问该资源的进程必须等待。
- 数据以字符流的形式写入管道,当管道写满时,写进程的write()系统调用将被阻塞,等待读进程将数据取走。当读进程将数据全部取走后,管道变空,此时读进程的read()系统调用将被阻塞;
- 写满才能读,读空才能继续写;
- 从管道读数据是一次性操作,数据一旦被读取,它就从管道中被抛弃,释放空间以便写更多的数据
实例:Linux Shell管道
Linux 管道使用竖线|连接多个命令,
|被称为管道符。- Linux 管道的具体语法格式如下:
command1 | command2 [ | commandN... ]
- Linux 管道的具体语法格式如下:
例如使用 mysqldump(一个数据库备份程序)来备份一个叫做 wiki 的数据库:
mysqldump -u root -p '123456' wiki > /tmp/wikidb.backup gzip -9 /tmp/wikidb.backup scp /tmp/wikidb.backup username@remote_ip:/backup/mysql/
上述这组命令主要做了如下任务:
mysqldump 命令用于将名为 wike 的数据库备份到文件 /tmp/wikidb.backup;其中
-u和-p选项分别指出数据库的用户名和密码。- gzip 命令用于压缩较大的数据库文件以节省磁盘空间;其中
-9表示最慢的压缩速度最好的压缩效果。 - scp 命令(secure copy,安全拷贝)用于将数据库备份文件复制到 IP 地址为 remote_ip 的备份服务器的 /backup/mysql/ 目录下。其中
username是登录远程服务器的用户名,命令执行后需要输入密码。 - 可以使用管道将 mysqldump、gzip、ssh 命令相连接,这样就避免了创建临时文件 /tmp/wikidb.backup
- gzip 命令用于压缩较大的数据库文件以节省磁盘空间;其中
使用管道后的命令如下所示:
mysqldump -u root -p '123456' wiki | gzip -9 | ssh username@remote_ip "cat > /backup/wikidb.gz"例如使用管道显示按用户名排序后的当前登录系统的用户的信息。
who列出当前用户,sort用每行开头的第一个字符来进行排序[c.biancheng.net]$ who | sort mozhiyan :0 2019-04-16 12:55 (:0) oozhiyan pts/0 2019-04-16 13:16 (:0)
消息传递
概念:进程间的数据交换以格式化的消息(Message)为单位。进程通过操作系统提供的“发送消息/接收消息”两个原语进行数据交换。
消息传递分类:
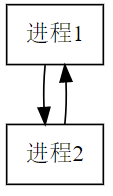
- 直接通信方式:发送进程直接把消息发送给接收进程,并将它挂在接收进程的消息缓冲队列上,接收进程从消息缓冲队列中取得消息,如上图所示。
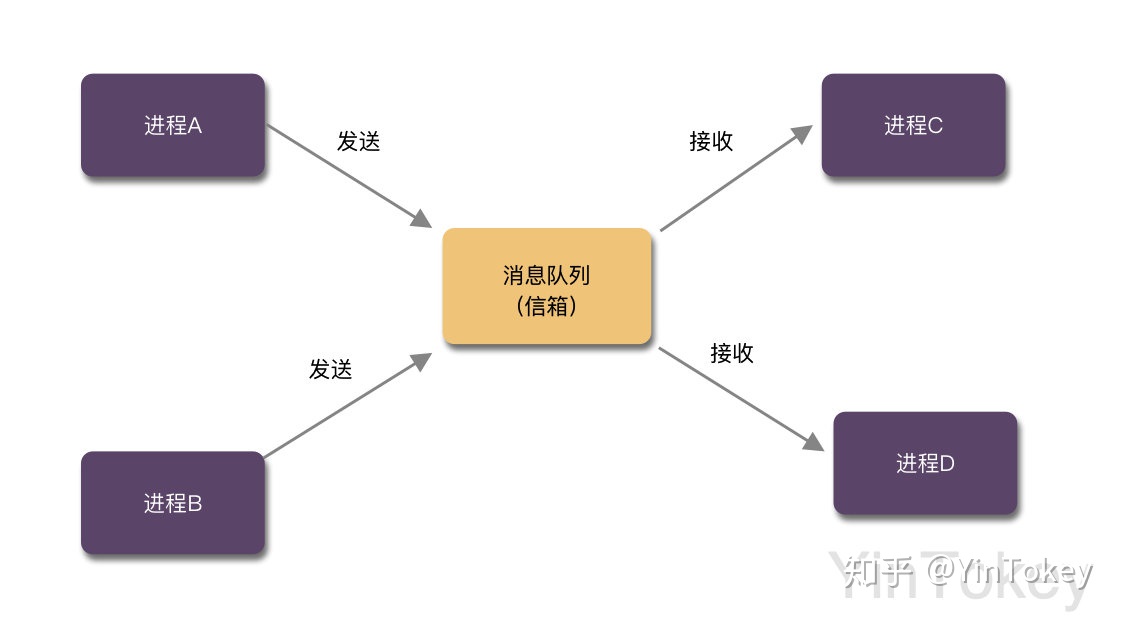
- 间接通信方式:发送进程把消息发送到某个中间实体,接收进程从中间实体取得消息。这种中间实体一般称为信箱,这种通信方式又称信箱通信方式。
三种通信方式比较
消息队列和管道都是内核对象,所执行的操作也都是系统调用,而这些数据最终是要存储在内存中执行的。所以消息队列和管道基本上都是4次拷贝:
- 从用户空间的buf中将数据拷贝到内核buf中(内核态位于用户态之下,原数据发送)
- 内核buf将数据拷贝到内存中(数据处理)
- 内存将数据拷贝到到内核buf(新数据返回)
- 内核buf将数据拷贝到用户空间的buf(新数据返回)
共享存储只需要两次拷贝:
- 从输入文件到共享内存区
- 从共享内存区输出到文件
常用进程管理命令
1.netstat -ano | findstr 80 #查看80端口的进程
2.taskkill /im cmd.exe #结束某进程
3.taskkill /pid 3378 #结束pid为3378的进程
Windows设备管理
设备管理为了克服设备与cpu速度不匹配问题,使主机和设备并行工作
i/o设备的控制方式
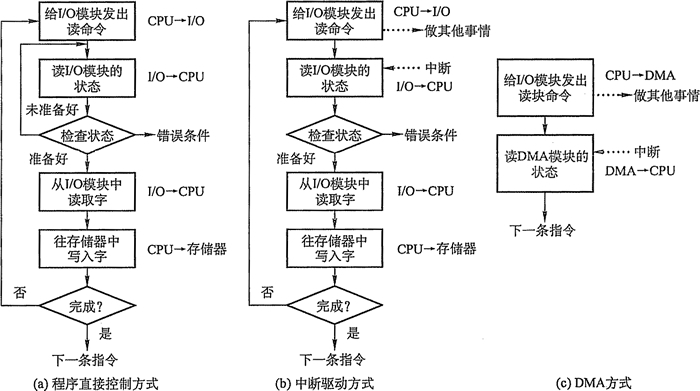
轮询方式:如图a所示,缺点是串行工作,需要等待设备,cpu参与数据传输,每次读一个字的数据,cpu花费大量时间等待输入输出的循环检测,效率低下。
中断方式:如图b所示,以字节为单位传输,不需要等待设备,部分并行工作(没有完全并行),cpu参与数据传输,i/o设备要向cpu发送中断信号,cpu才回来写入数据。
DMA方式:如图c所示,以块为单位传输,不需要等待设备,数据直接从i/o设备→内存或者内存→i/o设备。只在传送开始和结束需要cpu干预,数据传输是在控制器控制下完成。
- 优点:cpu不参与数据传输,并行工作
i/o通道控制方式:通道是特殊的处理机。以一组数据块为单位,只需向I/O通道发送一条I/O指令(输入/输出指令,是特权指令,用户态→内核态),以给出其所要执行的通道程序的首地址和要访问的I/O设备,通道接到该指令后,通过执行通道程序便可完成CPU指定的I/O任务,数据传送结束时向CPU发中断请求。
i/o通道与DMA方式的区别:
- DMA方式需要CPU来干预传输的数据块(数据块大小、传输的内存位置等),而通道方式中这些信息是由通道控制的。
- 每个DMA控制器对应一台设备与内存传递数据,而一个通道可以控制多台设备与内存的数据交换。
i/o缓冲区
缓冲区:是由操作系统内核进行管理,位于内核的存储区域。
背景:cpu运算速率远高于i/o设备速率,导致cpu停下等待输出设备。
缓冲区解决的问题:
- 缓和cpu和i/o设备间速率不匹配
- 减少处理器中断频率,减轻cpu负担
- 如果缓冲区为一位,需要100ms中断一次,那么缓存区为八位(存够八位数据),则时间放宽为800ms中断一次
- 解决数据粒度(数据单元大小)不匹配
- 提高cpu和i/o的并行性
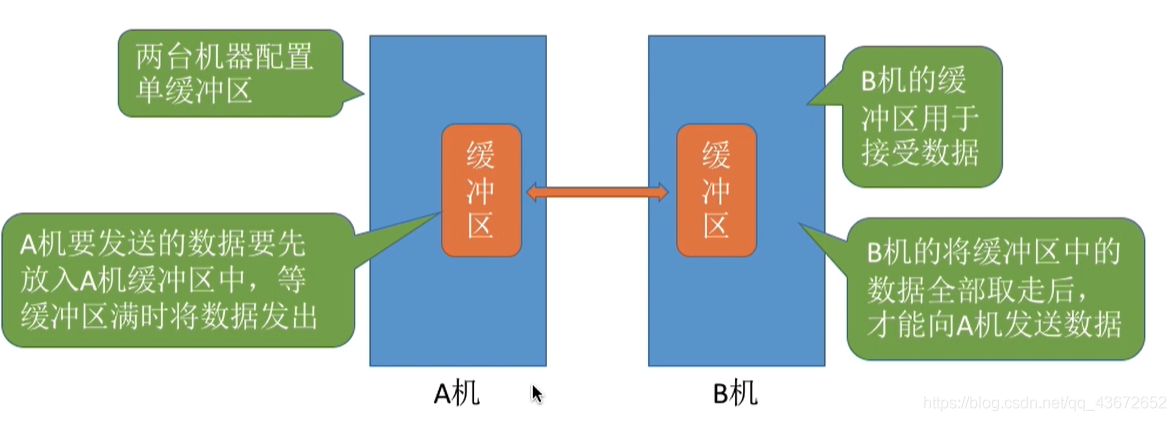
- 单缓冲区:当缓冲区不为空时不能往里面放入数据,只有缓冲区为空才能放入数据且一次放入的数据必须充满整个缓冲块,才能从缓冲区把数据传出。
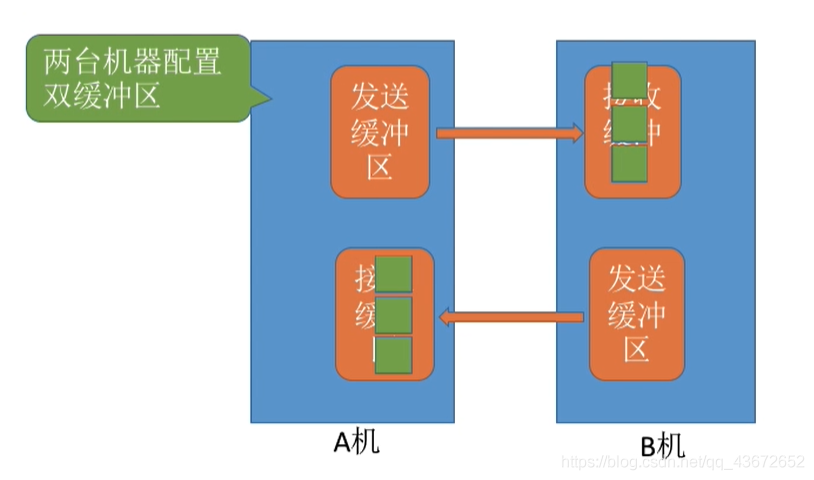
- 双缓冲区:同一时刻可以实现双向的数据传输
- 环形缓冲区:设置三个指针,用于指示可用缓冲区g的指针i,空缓冲区r的指针o,正在使用的缓冲区c的指针p。
- 1.getbuf过程。计算进程要使用缓冲区数据时,把i指针指示的g缓冲区提供给进程,令p指针指向g缓冲区第一个单元,让i指针指向下一个g缓冲区。当输入进程使用空缓冲区装数据时,把r指针所指的缓冲区提供给输入进程,同时把o指针指向下一个o缓冲区。
- 2.releasebuf过程。当计算进程把c缓冲区数据提取完毕时,c缓冲区改为r缓冲区。当输入进程把缓冲区装满时,把c缓冲区改成g缓冲区。
- 缓冲池:缓冲池由系统中共用的缓冲区组成。这些缓冲区按照同类型可以分为:空缓冲队列、装满输入数据的缓冲队列、装满输出数据的缓冲队列。
根据一个缓冲区在实际运算中扮演的功能不同,又设置了四种工作缓冲区:用于收容输入数据的工作缓冲区(hin) 、用于提取输入数据的工作缓冲区(sin) 、用于收容输出数据的工作缓冲区(hout) 、用于提取输出数据的工作缓冲区(sout) 。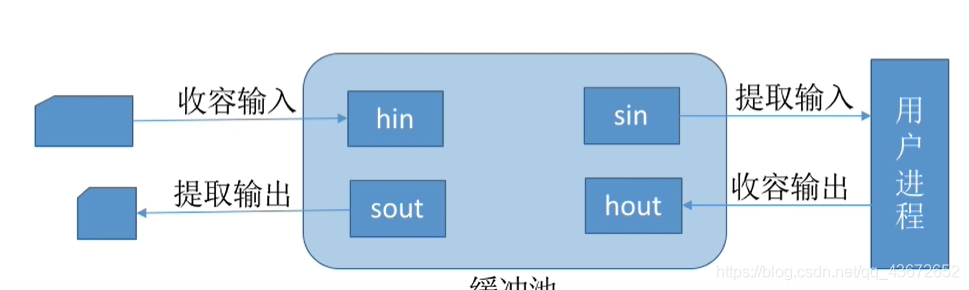
- 收容输入:从空缓冲队列摘下一个缓冲区,把数据输入其中,装满后加入输入队列
- 提取输入:从输入队列中摘下一个缓冲区,提取完数据后加入空缓冲区队列
- 收容输出:从空缓冲队列摘下一个缓冲区,把数据输出其中,装满后加入输出队列
- 提取输出:从输出队列中摘下一个缓冲区,提取完数据后加入空缓冲区队列
设备独立性
背景:作业执行前对设备提出申请时,指定物理设备会让分配很简单。但如果指定设备出现故障,则会被放到资源等待队列等待,将导致同类设备无法运行。例如主机开启,网卡故障会导致声卡等其他设备也不能运行。
设备独立性:不指定物理设备,指定逻辑设备,使用户作业和物理设备分开,需要建立物理设备和逻辑设备的映射。
磁盘调度算法
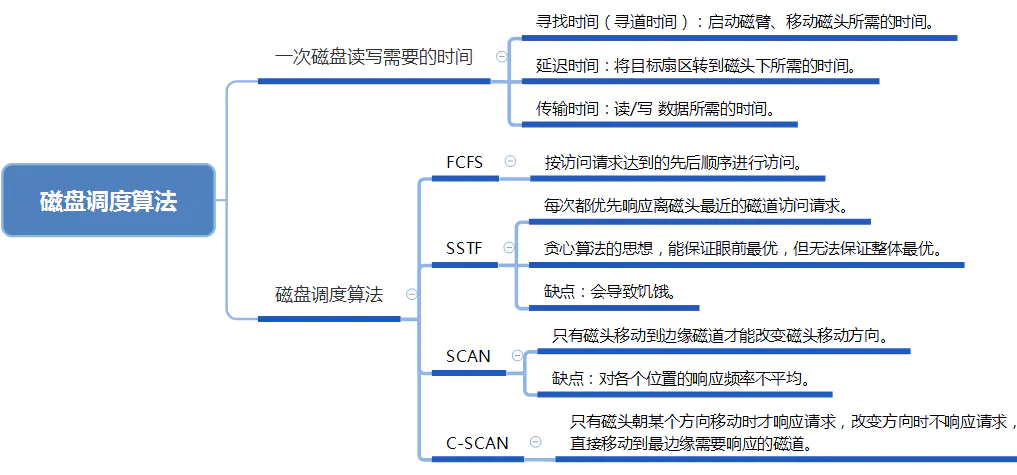
- SSTF:其缺点是对用户的服务请求的响应机会不是均等的
- SCAN:不仅考虑到目标磁道与当前磁道的距离,更优先考虑的是磁头的当前移动方向。例如,自里向外移动时,在磁头当前移动方向上选择与当前磁头所在磁道距离最近的,直到再无更外的磁道需要访问才将磁臂换向,自外向里移动。如果请求刚好在磁头前方加入队列,则它几乎马上就会得到服务;如果请求刚好在磁头后方加入队列,则它必须等待,直到磁头移到磁盘的另一端,反转方向,并返回。由于是摆动式的扫描方法,两侧磁道被访问的频率仍低于中间磁道。
- C-SCAN:循环扫描算法规定磁头单向移动。例如,只自里向外移动,当磁头移到最外的被访问磁道时,磁头立即返回到最里的欲访磁道,即将最小磁道号紧接着最大磁道号构成循环,进行扫描。相比于SCAN算法,平均寻道时间更长,但是对于各个位置磁道响应频率很平均。
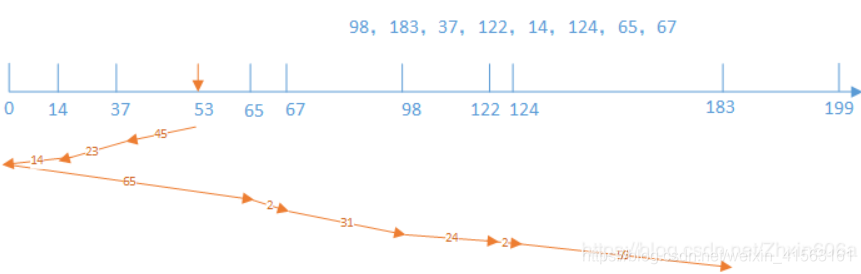
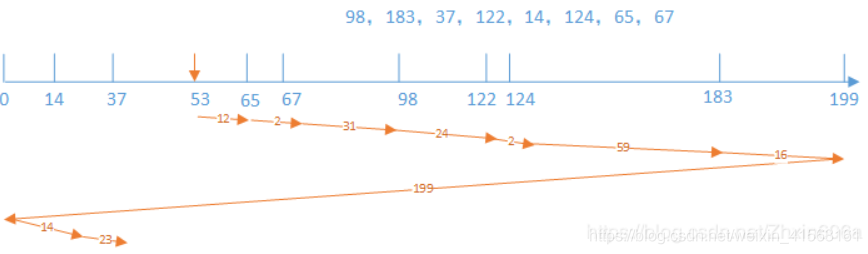
Windows日志
Windows系统日志是记录系统中硬件、软件和系统问题的信息,同时还可以监视系统中发生的事件。可以用来检查错误发生的原因,或者寻找受到攻击时攻击者留下的痕迹。
日志特点
- 系统内置的三个核心日志文件(System,Security和Application)默认大小均为20MB,记录事件数据超过20MB时,系统默认优先覆盖过期的日志记录。其它应用程序及服务日志默认最大为1MB,超过最大限制也优先覆盖过期的日志记录。
- Windwos操作系统默认没有提供删除特定日志记录的功能,仅提供了删除所有日志的操作功能。也就意味着日志记录ID(Event Record ID)应该是连续的,默认的排序方式应该是从大到小往下排列。
- 可以“删除”单条日志,实质上是隐藏。
日志查看
- 默认位置
C:/windows/System32/winevt/Logs,建议修改日志默认位置 - 利用事件查看器查看日志:开始->运行->输入
eventvwr->回车的方式快速打开该工具
日志分类
Windows主要有以下三类日志记录系统事件:应用程序日志、系统日志和安全日志。
- 系统日志:记录主要包括驱动程序、系统组件和应用软件的崩溃以及数据丢失错误等。系统日志中记录的时间类型由Windows NT/2000操作系统预先定义。 默认位置:
%SystemRoot%\System32\Winevt\Logs\System.evtx - 应用程序日志:包含由应用程序或系统程序记录的事件,主要记录程序运行方面的事件,例如数据库程序可以在应用程序日志中记录文件错误,默认位置:
%SystemRoot%\System32\Winevt\Logs\Application.evtx - 安全日志:记录系统的安全审计事件,包含各种类型的登录日志、对象访问日志、进程追踪日志、特权使用、帐号管理、策略变更、系统事件。安全日志也是调查取证中最常用到的日志。默认位置:
%SystemRoot%\System32\Winevt\Logs\Security.evtx - 前两者存储着故障排除信息,对于系统管理员更为有用;后者记录着事件审计信息,包括用户验证(登录、远程访问等)和特定用户在认证后对系统做了什么,对于调查人员而言,更有帮助。
日志安全设置
- 设置系统默认日志属性,保留90天以上系统日志,可为日后系统故障排除故障、安全事故追查入侵者提供依据。
- Windows Server 2008 R2 系统的审核功能在默认状态下并没有启用 ,建议开启审核策略。
日志分析
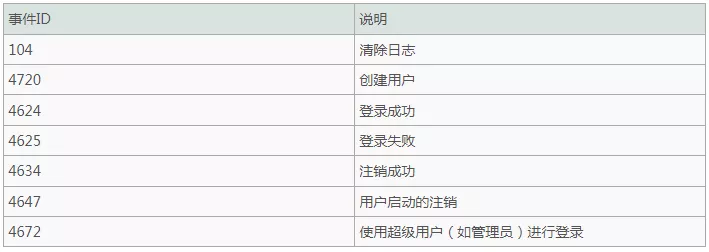
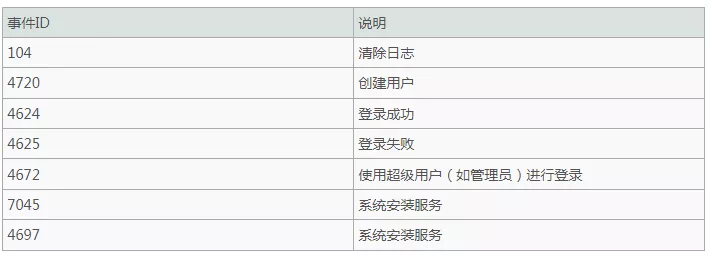
对于Windows事件日志分析,不同的EVENT ID代表了不同的意义,首要的过滤依据是EVENT ID
常见EVENT ID及其含义:
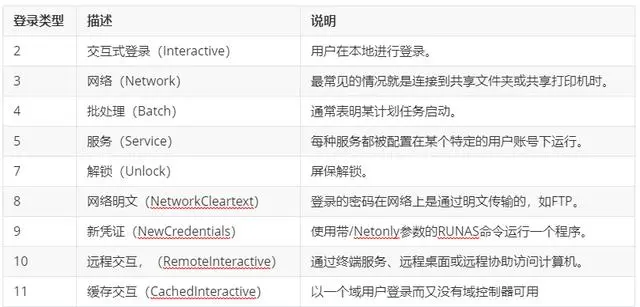
- 每个成功登录的事件都会标记一个登录类型 ,不同登录类型代表不同的方式
日志分析工具
- Log Parser
- LogParser Lizard
- Event Log Explorer
入侵情景分析
- BadUSB
- 在一些近源渗透案例中,攻击者使用BadUSB对公司员工进行攻击,对这类攻击进行追踪需要着重关注硬件设备安装到系统中的时间 ,展开追逐前,确保审核策略已正确配置。
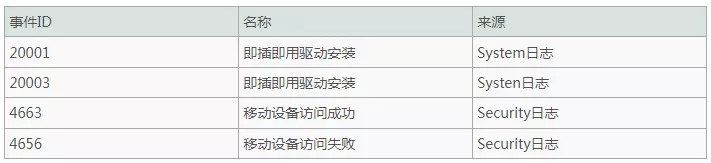
- WIFI钓鱼
- 在一些近源渗透案例中,攻击者使用WIFI伪造手段对办公区域进行钓鱼攻击,对这类攻击进行追踪需要着重分析系统访问过哪些关联的无线网络接入点及位置,展开追逐前,确保审核策略已正确配置。
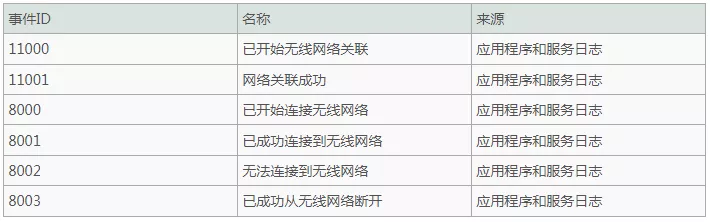
- 勒索病毒
- 在一些勒索病毒案例中,攻击者投放蠕虫病毒对局域网主机进行RDP(远程桌面)爆破,进而横向移动,对这类攻击进行追踪需要着重分析系统登陆事件,展开追逐前,确保审核策略已正确配置。
MAC OS基础
日志文件
Mac日志文件是记录电脑系统应用程序和服务活动的文件,其后缀名为.asl,全名为Apple System Log。Mac日志文件按天存储,主要分为系统日志、安装器日志、无线连接日志、VPN连接日志、内核日志、诊断日志和电源管理日志7大类别,存储格式均为.asl。由于Mac日志数据存储方式为二进制,在Window系统上并不能直接识别该文件,需要对其中的asl日志文件结构进行解析。
日志查看
系统日志文件夹 /var/log 系统日志文件 /var/log/system.log Mac 分析数据 /var/log/DiagnosticMessages 系统应用程序日志 /Library/Logs 系统报告 /Library/Logs/DiagnosticReports 用户应用程序日志 ~/Library/Logs 用户报告 ~/Library/Logs/DiagnosticReportsgrep -nE “123|abc” app.log #查询日志文件app.log中包含 关键字 123 或 包含 关键字 abc 的行,显示行号 grep -E -C5 “123” app.log #显示app.log中含有关键字"123"的行内容,以及之前之后的各5行内容 grep -E “123” app.log #显示app.log中含有关键字"123"的行内容 grep -i “magic” app.log #不分大小写的搜索匹配magic。默认情况下是区分大小写的 cat -n app.log | grep “error” --color #查询日志中含有某个关键字error的信息,显示行号,带颜色 cat -n app.log |grep “error” | more #使用more和less命令分页查看日志,空格键翻页 cat -n app.log |grep “error” > temp.txt #把日志保存到文件
MAC文件系统
- UFS:在 UFS 之前的文件系统最多只能使用 5% 的磁盘带宽,而 UFS 将这个数字提升到了 50%
- HFS+:苹果公司为替代他们的分层文件系统(HFS)而开发的一种文件系统
- APFS:是一个适用于macOS、iOS、tvOS和watchOS的文件系统,目前正在由苹果公司开发和部署。它的目的是解决HFS+(Mac OS Extend,APFS的前身)文件系统的核心问题。APFS针对闪存和固态存储设备进行优化,具有写入时复制等设计特点,使用I/O合并改进性能
Mac文件目录
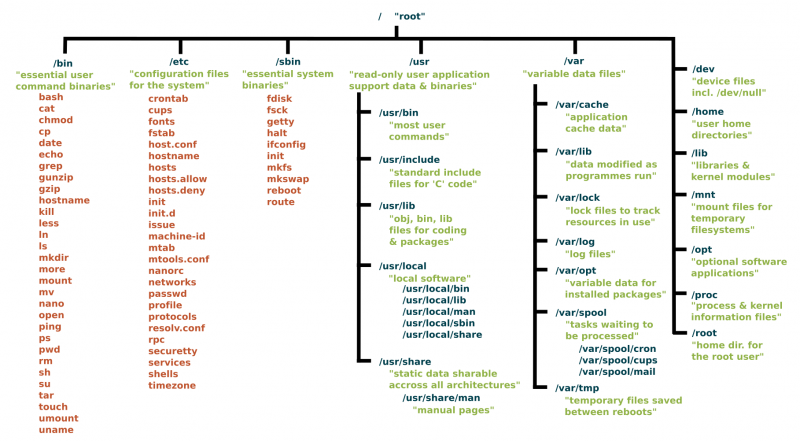
Mac特有目录
- /Applications 应用程序默认安装路径
- /Library 系统文件
- /Network 网络节点存放
- /System 只包含一个Library目录,存放了系统的绝大部分组件
- /Users 存放用户的数据
- /Volumes 存放挂载点
- /cores 内核转储文件存放目录。当一个进程崩溃时,如果系统允许则会产生转储文件。
- /private 存放了/tmp, /var, /etc等链接目录的目标目录。
Mac文件系统特点
由域确定文件的放置
- 在 macOS 中,文件系统被分为多个域,根据文件和资源的预期用途进行分离。
- 用户域包含特定于登录系统的用户的资源。虽然从技术上讲,它包含所有用户,但此域只反映当前用户在运行时的家庭目录。
- 本地域包含资源,例如当前计算机本地的应用程序,并共享给该计算机的所有用户。
- 网络域包含在局域网络所有用户之间共享的应用程序和文档等资源。
- 系统域包含由Apple安装的系统软件。系统域中的资源是系统运行所必需的。用户无法添加,删除或更改此域中的项目。
Mac基本操作命令
Mac用户管理命令
dscl . -list /Users #查看所有用户,仅显示用户名
dscl . -list /Users UniqueID #查看所有用户对应的ID
dscl . -read /Users/用户名 #查看指定用户的详细信息
dscl . -list /Groups 用户组id #查看用户组
dscl . -create /Users/kk UniqueID 888 #新建kk用户,id为888
dscl . -passwd /Users/sz 1234 #修改kk用户的密码
dscl . -delete /Users/kk #删除用户kk
dscl . -create /Groups/组名 #新建组
dscl . -append /Groups/组名 groupMembership kk #把kk添加到组
dscl . -delete /Groups/组名 groupMembership kk #把kk从组删除
dscl . -list /Groups GroupMembership #查看所有组下的用户
移动智能设备操作系统
Android
Android是基于Linux(不包含GNU组件)的自由及开放源代码的操作系统
Android日志文件
Android有四类日志文件,分别是:main, system, radio和events。
日志通过
/dev/log/main, /dev/log/system, /dev/log/radio, /dev/log/events四个设备文件来进行访问。main:应用程序日志
system:系统日志
radio:无线设备日志
events:诊断系统问题日志
Logger日志格式
main、system和radio三种类型的日志格式是相同的。日志格式如下所示:

- Priority:是一个整数,代表的是日志的优先级;
- 日志的优先级按重要程度不同划分为:
- V-详细(Verbose,最低优先级)
- D-调试(Debug)
- I-信息(Info)
- W-警告(Warning)
- E-错误(Error)
- F-致命(Fatal)
- S-静默(Silent,最高优先级,但不打印任何内容)
- 日志的优先级按重要程度不同划分为:
tag:是一个字符串,代表的是日志的标签;
message:是一个字符串,代表的是日志的内容。
events类型日志没有Priority标签
日志分析
Logcat
Android文件系统
Ext4
Android操作系统依托于Linux,所以主要的文件系统也是从Linux中发展而来,包括exFAT、ext3、ext4等,目前大多数手机仍使用Ext4。
F2FS
F2FS “Flash Friendly File System”,一种专门为闪存而生的文件系统,其优势就是小文件的传输速率更快。近年来不断的有旗舰机采用这一文件系统。
Ext4 vs F2FS
- F2FS 随机读写速度更快
- F2FS减少写的次数,延长固件寿命
- F2FS小文件读写速度更快,降低整理碎片开销
- Ext4 普及率更高,兼容性更好
- Ext 4 大文件读取远强于 F2FS
基本操作命令
adb:Android 调试桥
adb shell #进入Linuxshell模式
adb shell command #执行单条Linux命令
adb root #获取管理员权限
adb pull <远程路径> <本地路径> #从设备上下载文件到电脑
adb shell netcfg/ifconfig #显示ip
IOS
iOS属于类Unix的操作系统
IOS日志文件
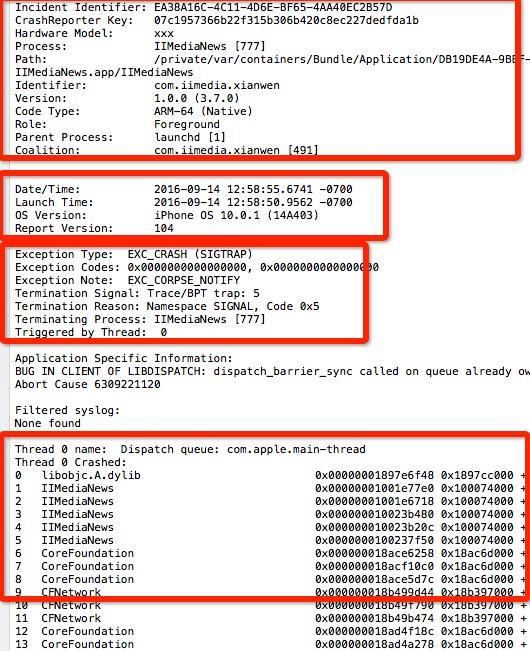
- 第一部分闪退进程的信息:
- Incident Identifier : 是崩溃报告的唯一标识符
- CrashReporter Key: 是与设备标识相对应的唯一键值。根据大量机子的出现频率可以判断是否是一个普遍的问题
- Hardware Model :标识设备类型。 如果很多崩溃日志都是来自相同的设备类型,说明只在某特定类型的设备上有问题
- Process:操作权限
- Path:崩溃文件的路径
- Identifier:项目标识符
- Version:版本号
- 第二部分基本信息
- 这部分包括闪退发生的日期Date/Time和时间Launch Time,设备的iOS版本OS Version
- 第三部分异常信息
- Exception Type:异常的类型
- Exception Codes :异常错误码
- Termination Reason:闪退的原因
- Triggered by Thread:出现问题的线程。首先确定在哪个线程中出了问题,其次再去定位。
基本操作命令
Korn Shell(Unix Shell)
w #显示当前系统活动的总信息
df /tmp #显示文件系统的总空间和可用空间
uname -a #显示系统全部信息
IOS文件系统
APFS 是 macOS、iOS、手表和 tvOS 中的默认文件系统。
iOS 标准目录:文件所在的位置
出于安全目的,iOS 应用与文件系统的交互仅限于应用沙盒目录内的目录。
通常禁止应用在沙盒之外访问或创建文件
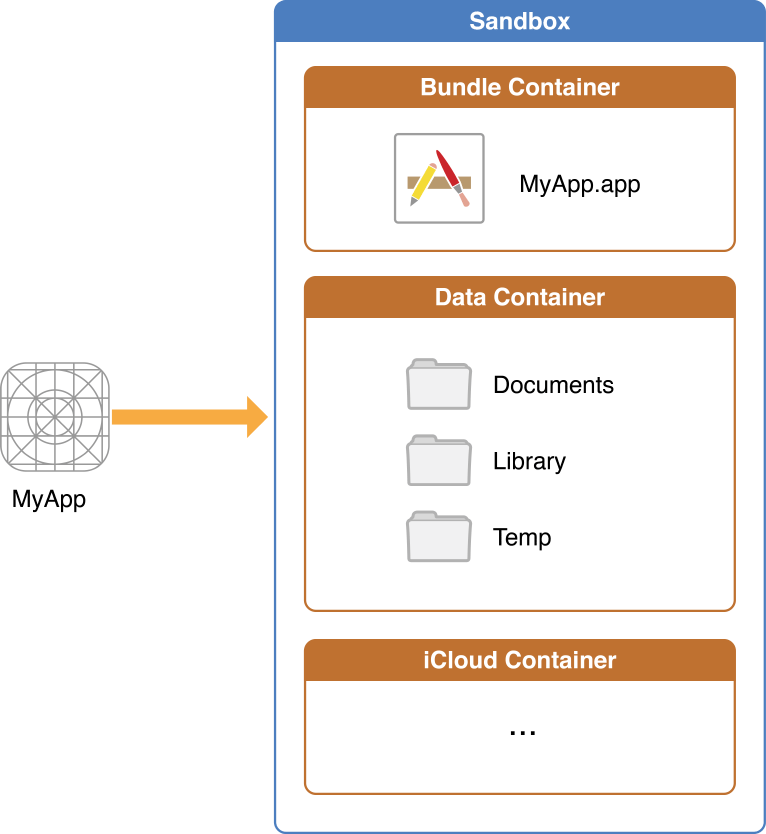
- Documents:用户数据
- Library:非用户数据,存储特定资源
- Temp:临时文件,可能定时由系统清除
- MyApp.app:应用程序的包
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至1694933467@qq.com